电脑系统多线程运行机制有哪些_电脑系统多线程运行机制
1.浅谈linux 多线程编程和 windows 多线程编程的异同
2.java多线程开发的同步机制有哪些
3.线程可以独立执行程序吗
4.windows 怎样在调度线程到多核
5.多线程是什么呀
6.多线程编程怎么回事啊
首先子线程不是独立的空间啊!要不也有同步锁了!
java中运行多线程时是一会运行这个线程,一会运行那个线程……随机运行的。因为运行的速度快时间短,所以就给人感觉线程是同时运行的。
只要出错了,java程序立马停止运行!
浅谈linux 多线程编程和 windows 多线程编程的异同
一、线程的概念
一般来说,我们把正在计算机中执行的程序叫做"进程"(Process) ,而不将其称为程序(Program)。所谓"线程"(Thread),是"进程"中某个单一顺序的控制流。
新兴的操作系统,如Mac,Windows NT,Windows 95等,大多采用多线程的概念,把线程视为基本执行单位。线程也是Java中的相当重要的组成部分之一。
甚至最简单的Applet也是由多个线程来完成的。在Java中,任何一个Applet的paint()和update()方法都是由AWT(Abstract Window Toolkit)绘图与事件处理线程调用的,而Applet 主要的里程碑方法——init(),start(),stop()和destory() ——是由执行该Applet的应用调用的。
单线程的概念没有什么新的地方,真正有趣的是在一个程序中同时使用多个线程来完成不同的任务。某些地方用轻量进程(Lightweig ht Process)来代替线程,线程与真正进程的相似性在于它们都是单一顺序控制流。然而线程被认为轻量是由于它运行于整个程序的上下文内,能使用整个程序共有的资源和程序环境。
作为单一顺序控制流,在运行的程序内线程必须拥有一些资源作为必要的开销。例如,必须有执行堆栈和程序计数器。在线程内执行的代码只在它的上下文中起作用,因此某些地方用"执行上下文"来代替"线程"。
二、线程属性
为了正确有效地使用线程,必须理解线程的各个方面并了解Java 实时系统。必须知道如何提供线程体、线程的生命周期、实时系统如 何调度线程、线程组、什么是幽灵线程(Demo nThread)。
(1)线程体
所有的操作都发生在线程体中,在Java中线程体是从Thread类继承的run()方法,或实现Runnable接口的类中的run()方法。当线程产生并初始化后,实时系统调用它的run()方法。run()方法内的代码实现所产生线程的行为,它是线程的主要部分。
(2)线程状态
附图表示了线程在它的生命周期内的任何时刻所能处的状态以及引起状态改变的方法。这图并不是完整的有限状态图,但基本概括了线程中比较感兴趣和普遍的方面。以下讨论有关线程生命周期以此为据。
●新线程态(New Thread)
产生一个Thread对象就生成一个新线程。当线程处于"新线程"状态时,仅仅是一个空线程对象,它还没有分配到系统资源。因此只能启动或终止它。任何其他操作都会引发异常。
●可运行态(Runnable)
start()方法产生运行线程所必须的资源,调度线程执行,并且调用线程的run()方法。在这时线程处于可运行态。该状态不称为运行态是因为这时的线程并不总是一直占用处理机。特别是对于只有一个处理机的PC而言,任何时刻只能有一个处于可运行态的线程占用处理 机。Java通过调度来实现多线程对处理机的共享。
●非运行态(Not Runnable)
当以下事件发生时,线程进入非运行态。
①suspend()方法被调用;
②sleep()方法被调用;
③线程使用wait()来等待条件变量;
④线程处于I/O等待。
●死亡态(Dead)
当run()方法返回,或别的线程调用stop()方法,线程进入死亡态 。通常Applet使用它的stop()方法来终止它产生的所有线程。
(3)线程优先级
虽然我们说线程是并发运行的。然而事实常常并非如此。正如前面谈到的,当系统中只有一个CPU时,以某种顺序在单CPU情况下执行多线程被称为调度(scheduling)。Java采用的是一种简单、固定的调度法,即固定优先级调度。这种算法是根据处于可运行态线程的相对优先级来实行调度。当线程产生时,它继承原线程的优先级。在需要时可对优先级进行修改。在任何时刻,如果有多条线程等待运行,系统选择优先级最高的可运行线程运行。只有当它停止、自动放弃、或由于某种原因成为非运行态低优先级的线程才能运行。如果两个线程具有相同的优先级,它们将被交替地运行。
Java实时系统的线程调度算法还是强制性的,在任何时刻,如果一个比其他线程优先级都高的线程的状态变为可运行态,实时系统将选择该线程来运行。
(4)幽灵线程
任何一个Java线程都能成为幽灵线程。它是作为运行于同一个进程内的对象和线程的服务提供者。例如,HotJava浏览器有一个称为" 后台阅读器"的幽灵线程,它为需要的对象和线程从文件系统或网络读入。
幽灵线程是应用中典型的独立线程。它为同一应用中的其他对象和线程提供服务。幽灵线程的run()方法一般都是无限循环,等待服务请求。
(5)线程组
每个Java线程都是某个线程组的成员。线程组提供一种机制,使得多个线程集于一个对象内,能对它们实行整体操作。譬如,你能用一个方法调用来启动或挂起组内的所有线程。Java线程组由ThreadGroup类实现。
当线程产生时,可以指定线程组或由实时系统将其放入某个缺省的线程组内。线程只能属于一个线程组,并且当线程产生后不能改变它所属的线程组。
三、多线程程序
对于多线程的好处这就不多说了。但是,它同样也带来了某些新的麻烦。只要在设计程序时特别小心留意,克服这些麻烦并不算太困难。
(1)同步线程
许多线程在执行中必须考虑与其他线程之间共享数据或协调执行状态。这就需要同步机制。在Java中每个对象都有一把锁与之对应。但Java不提供单独的lock和unlock操作。它由高层的结构隐式实现, 来保证操作的对应。(然而,我们注意到Java虚拟机提供单独的monito renter和monitorexit指令来实现lock和unlo
ck操作。)
synchronized语句计算一个对象引用,试图对该对象完成锁操作, 并且在完成锁操作前停止处理。当锁操作完成synchronized语句体得到执行。当语句体执行完毕(无论正常或异常),解锁操作自动完成。作为面向对象的语言,synchronized经常与方法连用。一种比较好的办法是,如果某个变量由一个线程赋值并由别的线程引用或赋值,那么所有对该变量的访问都必须在某个synchromized语句或synchronized方法内。
现在假设一种情况:线程1与线程2都要访问某个数据区,并且要求线程1的访问先于线程2, 则这时仅用synchronized是不能解决问题的。这在Unix或Windows NT中可用Simaphore来实现。而Java并不提供。在Java中提供的是wait()和notify()机制。使用如下:
synchronized method-1(…){ call by thread 1.
‖access data area;
available=true;
notify()
}
synchronized method-2(…){‖call by thread 2.
while(!available)
try{
wait();‖wait for notify().
}catch (Interrupted Exception e){
}
‖access data area
}
其中available是类成员变量,置初值为false。
如果在method-2中检查available为假,则调用wait()。wait()的作用是使线程2进入非运行态,并且解锁。在这种情况下,method-1可以被线程1调用。当执行notify()后。线程2由非运行态转变为可运行态。当method-1调用返回后。线程2可重新对该对象加锁,加锁成功后执行wait()返回后的指令。这种机制也能适用于其他更复杂的情况。
(2)死锁
如果程序中有几个竞争资源的并发线程,那么保证均衡是很重要的。系统均衡是指每个线程在执行过程中都能充分访问有限的资源。系统中没有饿死和死锁的线程。Java并不提供对死锁的检测机制。对大多数的Java程序员来说防止死锁是一种较好的选择。最简单的防止死锁的方法是对竞争的资源引入序号,如果一个线程需要几个资源,那么它必须先得到小序号的资源,再申请大序号的资源。
四、线程和进程的比较
进程是资源分配的基本单位。所有与该进程有关的资源,都被记录在进程控制块PCB中。以表示该进程拥有这些资源或正在使用它们。
另外,进程也是抢占处理机的调度单位,它拥有一个完整的虚拟地址空间。
与进程相对应,线程与资源分配无关,它属于某一个进程,并与进程内的其他线程一起共享进程的资源。
当进程发生调度时,不同的进程拥有不同的虚拟地址空间,而同一进程内的不同线程共享同一地址空间。
线程只由相关堆栈(系统栈或用户栈)寄存器和线程控制表TCB组成。寄存器可被用来存储线程内的局部变量,但不能存储其他线程的相关变量。
发生进程切换与发生线程切换时相比较,进程切换时涉及到有关资源指针的保存以及地址空间的变化等问题;线程切换时,由于同不进程内的线程共享资源和地址 空间,将不涉及资源信息的保存和地址变化问题,从而减少了操作系统的开销时间。而且,进程的调度与切换都是由操作系统内核完成,而线程则既可由操作系统内 核完成,也可由用户程序进行。
五、线程的适用范围
典型的应用
1.服务器中的文件管理或通信控制
2.前后台处理
3.异步处理
六、线程的执行特性
一个线程必须处于如下四种可能的状态之一:
初始态:一个线程调用了new方法之后,并在调用start方法之前的所处状态。在初始态中,可以调用start和stop方法。
Runnable:一旦线程调用了start 方法,线程就转到Runnable 状态,注意,如果线程处于Runnable状态,它也有可能不在运行,这是因为还有优先级和调度问题。
阻塞/ NonRunnable:线程处于阻塞/NonRunnable状态,这是由两种可能性造成的:要么是因挂起而暂停的,要么是由于某些原因而阻塞的,例如包括等待IO请求的完成。 退出:线程转到退出状态,这有两种可能性,要么是run方法执行结束,要么是调用了stop方法。
最后一个概念就是线程的优先级,线程可以设定优先级,高优先级的线程可以安排在低优先级线程之前完成。一个应用程序可以通过使用线程中的方法setPriority(int),来设置线程的优先级大小。
线程有5种基本操作:
派生:线程在进程内派生出来,它即可由进程派生,也可由线程派生。
阻塞(Block):如果一个线程在执行过程中需要等待某个事件发生,则被阻塞。
激活(unblock):如果阻塞线程的事件发生,则该线程被激活并进入就绪队列。
调度(schedule):选择一个就绪线程进入执行状态。
结束(Finish):如果一个线程执行结束,它的寄存器上下文以及堆栈内容等将被释放。
七、线程的分类
线程有两个基本类型:
用户级线程:管理过程全部由用户程序完成,操作系统内核心只对进程进行管理。
系统级线程(核心级线程):由操作系统内核进行管理。操作系统内核给应用程序提供相应的系统调用和应用程序接口API,以使用户程序可以创建、执行、撤消线程。
附:线程举例
1. SUN Solaris 2.3
Solaris支持内核线程、轻权进程和用户线程。一个进程可有大量用户线程;大量用户线程复用少量的轻权进程,轻权进程与内核线程一一对应。
用户级线程在调用核心服务时(如文件读写),需要“捆绑(bound)”在一个LWP上。永久捆绑(一个LWP固定被一个用户级线程占用,该LWP移到LWP池之外)和临时捆绑(从LWP池中临时分配一个未被占用的LWP)。
在调用系统服务时,如果所有LWP已被其他用户级线程所占用(捆绑),则该线程阻塞直到有可用的LWP。
如果LWP执行系统线程时阻塞(如read()调用),则当前捆绑在LWP上的用户级线程也阻塞。
¨ 有关的C库函数
/* 创建用户级线程 */
int thr_create(void *stack_base, size_t stack_size,
void *(*start_routine)(void *), void *arg, long flags,
thread_t *new_thread_id);
其中flags包括:THR_BOUND(永久捆绑), THR_NEW_LWP(创建新LWP放入LWP池),若两者同时指定则创建两个新LWP,一个永久捆绑而另一个放入LWP池。
? 有关的系统调用
/* 在当前进程中创建LWP */
int _lwp_create(ucontext_t *contextp, unsigned long flags,
lwpid_t *new_lwp_id);
/* 构造LWP上下文 */
void _lwp_makecontext(ucontext_t *ucp,
void (*start_routine)( void *), void *arg,
void *private, caddr_t stack_base, size_t stack_size);
/* 注意:没有进行“捆绑”操作的系统调用 */
2. Windows NT
NT线程的上下文包括:寄存器、核心栈、线程环境块和用户栈。
NT线程状态
(1) 就绪状态:进程已获得除处理机外的所需资源,等待执行。
(2) 备用状态:特定处理器的执行对象,系统中每个处理器上只能有一个处于备用状态的线程。
(3) 运行状态:完成描述表切换,线程进入运行状态,直到内核抢先、时间片用完、线程终止或进行等待状态。
(4) 等待状态:线程等待对象句柄,以同步它的执行。等待结束时,根据优先级进入运行、就绪状态。
(5) 转换状态:线程在准备执行而其内核堆栈处于外存时,线程进入转换状态;当其内核堆栈调回内存,线程进入就绪状态。
(6) 终止状态:线程执行完就进入终止状态;如执行体有一指向线程对象的指针,可将线程对象重新初始化,并再次使用。
NT线程的有关API
CreateThread()函数在调用进程的地址空间上创建一个线程,以执行指定的函数;返回值为所创建线程的句柄。
ExitThread()函数用于结束本线程。
SuspendThread()函数用于挂起指定的线程。
ResumeThread()函数递减指定线程的挂起计数,挂起计数为0时,线程恢复执行。
java多线程开发的同步机制有哪些
首先我们讲讲为什么要采用多线程编程,其实并不是所有的程序都必须采用多线程,有些时候采用多线程,性能还没有单线程好。所以我们要搞清楚,什么时候采用多线程。采用多线程的好处如下:
(1)因为多线程彼此之间采用相同的地址空间,共享大部分的数据,这样和多进程相比,代价比较节俭,因为多进程的话,启动新的进程必须分配给它独立的地址空间,这样需要数据表来维护代码段,数据段和堆栈段等等。
(2)多线程和多进程相比,一个明显的优点就是线程之间的通信了,对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过通信的方式进行,这种方式不仅费时,而且很不方便。但是对于多线程就不一样了。他们之间可以直接共享数据,比如最简单的方式就是共享全局变量。但是共享全部变量也要注意哦,呵呵,必须注意同步,不然后果你知道的。呵呵。
(3)在多cpu的情况下,不同的线程可以运行不同的cpu下,这样就完全并行了。
反正我觉得在这种情况下,采用多线程比较理想。比如说你要做一个任务分2个步骤,你为提高工作效率,你可以多线程技术,开辟2个线程,第一个线程就做第一步的工作,第2个线程就做第2步的工作。但是你这个时候要注意同步了。因为只有第一步做完才能做第2步的工作。这时,我们可以采用同步技术进行线程之间的通信。
针对这种情况,我们首先讲讲多线程之间的通信,在windows平台下,多线程之间通信采用的方法主要有:
(1)共享全局变量,这种方法是最容易想到的,呵呵,那就首先讲讲吧,比如说吧,上面的问题,第一步要向第2步传递收据,我们可以之间共享全局变量,让两个线程之间传递数据,这时主要考虑的就是同步了,因为你后面的线程在对数据进行操作的时候,你第一个线程又改变了数据的内容,你不同步保护,后果很严重的。你也知道,这种情况就是读脏数据了。在这种情况下,我们最容易想到的同步方法就是设置一个bool flag了,比如说在第2个线程还没有用完数据前,第一个线程不能写入。有时在2个线程所需的时间不相同的时候,怎样达到最大效率的同步,就比较麻烦了。咱们可以多开几个缓冲区进行操作。就像生产者消费者一样了。如果是2个线程一直在跑的,由于时间不一致,缓冲区迟早会溢出的。在这种情况下就要考虑了,是不让数据写入还是让数据覆盖掉老的数据,这时候就要具体问题具体分析了。就此打住,呵呵。就是用bool变量控制同步,linux 和windows是一样的。
既然讲道了这里,就再讲讲其它同步的方法。同样 针对上面的这个问题,共享全局变量同步问题。除了采用bool变量外,最容易想到的方法就是互斥量了。呵呵,也就是传说中的加锁了。windows下加锁和linux下加锁是类似的。采用互斥量进行同步,要想进入那段代码,就先必须获得互斥量。
linux上互斥量的函数是:
windows下互斥量的函数有:createmutex 创建一个互斥量,然后就是获得互斥量waitforsingleobject函数,用完了就释放互斥量ReleaseMutex(hMutex),当减到0的时候 内核会才会释放其对象。下面是windows下与互斥的几个函数原型。
HANDLE WINAPI CreateMutex(
__in LPSECURITY_ATTRIBUTES lpMutexAttributes,
__in BOOL bInitialOwner,
__in LPCTSTR lpName
);
可以可用来创建一个有名或无名的互斥量对象
第一参数 可以指向一个结构体SECURITY_ATTRIBUTES 一般可以设为null;
第二参数 指当时的函数是不是感应感应状态 FALSE为当前拥有者不会创建互斥
第三参数 指明是否是有名的互斥对象 如果是无名 用null就好。
DWORD WINAPI WaitForSingleObject(
__in HANDLE hHandle,
__in DWORD dwMilliseconds
);
第一个是 创建的互斥对象的句柄。第二个是 表示将在多少时间之后返回 如果设为宏INFINITE 则不会返回 直到用户自己定义返回。
对于linux操作系统,互斥也是类似的,只是函数不同罢了。在linux下,和互斥相关的几个函数也要闪亮登场了。
pthread_mutex_init函数:初始化一个互斥锁;
pthread_mutex_destroy函数:注销一个互斥锁;
pthread_mutex_lock函数:加锁,如果不成功,阻塞等待;
pthread_mutex_unlock函数:解锁;
pthread_mutex_trylock函数:测试加锁,如果不成功就立即返回,错误码为EBUSY;
至于这些函数的用法,google上一搜,就出来了,呵呵,在这里不多讲了。windows下还有一个可以用来保护数据的方法,也是线程同步的方式
就是临界区了。临界区和互斥类似。它们之间的区别是,临界区速度快,但是它只能用来同步同一个进程内的多个线程。临界区的获取和释放函数如下:
EnterCriticalSection() 进入临界区; LeaveCriticalSection()离开临界区。 对于多线程共享内存的东东就讲到这里了。
(2)采用消息机制进行多线程通信和同步,windows下面的的消息机制的函数用的多的就是postmessage了。Linux下的消息机制,我用的较少,就不在这里说了,如果谁熟悉的,也告诉我,呵呵。
(3)windows下的另外一种线程通信方法就是事件和信号量了。同样针对我开始举得例子,2个线程同步,他们之间传递信息,可以采用事件(Event)或信号量(Semaphore),比如第一个线程完成生产的数据后,就必须告诉第2个线程,他已经把数据准备好了,你可以来取走了。第2个线程就把数据取走。呵呵,这里可以采用消息机制,当第一个线程准备好数据后,就直接postmessage给第2个线程,按理说采用postmessage一个线程就可以搞定这个问题了。呵呵,不是重点,省略不讲了。
对于linux,也有类似的方法,就是条件变量了,呵呵,这里windows和linux就有不同了。要特别讲讲才行。
对于windows,采用事件和信号量同步时候,都会使用waitforsingleobject进行等待的,这个函数的第一个参数是一个句柄,在这里可以是Event句柄,或Semaphore句柄,第2个参数就是等待的延迟,最终等多久,单位是ms,如果这个参数为INFINITE,那么就是无限等待了。释放信号量的函数为ReleaseSemaphore();释放事件的函数为SetEvent。当然使用这些东西都要初始化的。这里就不讲了。Msdn一搜,神马都出来了,呵呵。神马都是浮云!
对于linux操作系统,是采用条件变量来实现类似的功能的。Linux的条件变量一般都是和互斥锁一起使用的,主要的函数有:
pthread_mutex_lock ,
pthread_mutex_unlock,
pthread_cond_init
pthread_cond_signal
pthread_cond_wait
pthread_cond_timewait
为了和windows操作系统进行对比,我用以下表格进行比较:
对照以上表格,总结如下:
(1) Pthread_cleanup_push,Pthread_cleanup_pop:
这一对函数push和pop的作用是当出现异常退出时,做一些清除操作,即当在push和pop函数之间异常退出,包括调用pthread_exit退出,都会执行push里面的清除函数,如果有多个push,注意是是栈,先执行后面的那个函数,在执行前面的函数,但是注意当在这2个函数之间通过return 退出的话,执不执行push后的函数就看pop函数中的参数是不是为0了。还有当没有异常退出时,等同于在这里面return退出的情况,即:当pop函数参数不为0时,执行清除操作,当pop函数参数为0时,不执行push函数中的清除函数。
(2)linux的pthread_cond_signal和SetEvent的不同点
Pthread_cond_singal释放信号后,当没有Pthread_cond_wait,信号马上复位了,这点和SetEvent不同,SetEvent是不会复位的。详解如下:
条件变量的置位和复位有2种常用模型:第一种模型是当条件变量置位时(signaled)以后,如果当前没有线程在等待,其状态会保持为置位(signaled),直到有等待的线程进入被触发,其状态才会变为unsignaled,这种模型以采用Windows平台上的Auto-set Event 为代表。
第2种模型则是Linux平台的pthread所采用的模型,当条件变量置位(signaled)以后,即使当前没有任何线程在等待,其状态也会恢复为复位(unsignaled)状态。
条件变量在Linux平台上的这种模型很难说好坏,在实际应用中,我们可以对
代码稍加改进就可以避免这种差异的发生。由于这种差异只会发生在触发没有被线程等待在条件变量的时刻,因此我们只需要掌握好触发的时机即可。最简单的做法是增加一个计数器记录等待线程的个数,在决定触发条件变量前检查该变量即可。
示例 使用 pthread_cond_wait() 和 pthread_cond_signal()
pthread_mutex_t count_lock;
pthread_cond_t count_nonzero;
unsigned count;
decrement_count()
{
pthread_mutex_lock(&count_lock);
while (count == 0)
pthread_cond_wait(&count_nonzero, &count_lock);
count = count - 1;
pthread_mutex_unlock(&count_lock);
}
increment_count()
{
pthread_mutex_lock(&count_lock);
if (count == 0)
pthread_cond_signal(&count_nonzero);
count = count + 1;
pthread_mutex_unlock(&count_lock);
}
(3) 注意Pthread_cond_wait条件返回时互斥锁的解锁问题
extern int pthread_cond_wait __P ((pthread_cond_t *__cond,pthread_mutex_t *__mutex));
调用这个函数时,线程解开mutex指向的锁并被条件变量cond阻塞。线程可以被函数pthread_cond_signal和函数 pthread_cond_broadcast唤醒线程被唤醒后,它将重新检查判断条件是否满足,如果还不满足,一般说来线程应该仍阻塞在这里,被等待被下一次唤醒。如果在多线程中采用pthread_cond_wait来等待时,会首先释放互斥锁,当等待的信号到来时,再次获得互斥锁,因此在之后要注意手动解锁。举例如下:
#include
#include
#include
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; /*初始化互斥锁*/
pthread_cond_t cond = PTHREAD_COND_INITIALIZER; //初始化条件变量
void *thread1(void *);
void *thread2(void *);
int i=1;
int main(void)
{
pthread_t t_a;
pthread_t t_b;
pthread_create(&t_a,NULL,thread1,(void *)NULL);/*创建进程t_a*/
pthread_create(&t_b,NULL,thread2,(void *)NULL); /*创建进程t_b*/
pthread_join(t_b, NULL);/*等待进程t_b结束*/
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&cond);
exit(0);
}
void *thread1(void *junk)
{
for(i=1;i<=9;i++)
{
printf("IN one\n");
pthread_mutex_lock(&mutex);//
if(i%3==0)
pthread_cond_signal(&cond);/*,发送信号,通知t_b进程*/
else
printf("thead1:%d\n",i);
pthread_mutex_unlock(&mutex);//*解锁互斥量*/
printf("Up Mutex\n");
sleep(3);
}
}
void *thread2(void *junk)
{
while(i<9)
{
printf("IN two \n");
pthread_mutex_lock(&mutex);
if(i%3!=0)
pthread_cond_wait(&cond,&mutex);/*等待*/
printf("thread2:%d\n",i);
pthread_mutex_unlock(&mutex);
printf("Down Mutex\n");
sleep(3);
}
}
输出如下:
IN one
thead1:1
Up Mutex
IN two
IN one
thead1:2
Up Mutex
IN one
thread2:3
Down Mutex
Up Mutex
IN one
thead1:4
Up Mutex
IN two
IN one
thead1:5
Up Mutex
IN one
Up Mutex
thread2:6
Down Mutex
IN two
thread2:6
Down Mutex
IN one
thead1:7
Up Mutex
IN one
thead1:8
Up Mutex
IN two
IN one
Up Mutex
thread2:9
Down Mutex
注意蓝色的地方,有2个thread2:6,其实当这个程序多执行几次,i=3和i=6时有可能多打印几个,这里就是竞争锁造成的了。
(4)另外要注意的Pthread_cond_timedwait等待的是绝对时间,这个和WaitForSingleObject是不同的,Pthread_cond_timedwait在网上也有讨论。如下:这个问题比较经典,我把它搬过来。
thread_a :
pthread_mutex_lock(&mutex);
//do something
pthread_mutex_unlock(&mutex)
thread_b:
pthread_mutex_lock(&mutex);
//do something
pthread_cond_timedwait(&cond, &mutex, &tm);
pthread_mutex_unlock(&mutex)
有如上两个线程thread_a, thread_b,现在如果a已经进入了临界区,而b同时超时了,那么b会从pthread_cond_timedwait返回吗?如果能返回,那岂不是a,b都在临界区?如果不能返回,那pthread_cond_timedwait的定时岂不是就不准了?
大家讨论有价值的2点如下:
(1) pthread_cond_timedwait (pthread_cond_t *cv, pthread_mutex_t *external_mutex, const struct timespec *abstime) -- This function is a time-based variant of pthread_cond_wait. It waits up to abstime amount of time for cv to be notified. If abstime elapses before cv is notified, the function returns back to the caller with an ETIME result, signifying that a timeout has occurred. Even in the case of timeouts, the external_mutex will be locked when pthread_cond_timedwait returns.
(2) 2.1 pthread_cond_timedwait行为和pthread_cond_wait一样,在返回的时候都要再次lock mutex.
2 .2pthread_cond_timedwait所谓的如果没有等到条件变量,超时就返回,并不确切。
如果pthread_cond_timedwait超时到了,但是这个时候不能lock临界区,pthread_cond_timedwait并不会立即返回,但是在pthread_cond_timedwait返回的时候,它仍在临界区中,且此时返回值为ETIMEDOUT。
关于pthread_cond_timedwait超时返回的问题,我也认同观点2。
附录:
int pthread_create(pthread_t *restrict tidp,const pthread_attr_t *restrict_attr,void*(*start_rtn)(void*),void *restrict arg);
返回值:若成功则返回0,否则返回出错编号
返回成功时,由tidp指向的内存单元被设置为新创建线程的线程ID。attr参数用于制定各种不同的线程属性。新创建的线程从start_rtn函数的地址开始运行,该函数只有一个无指针参数arg,如果需要向start_rtn函数传递的参数不止一个,那么需要把这些参数放到一个结构中,然后把这个结构的地址作为arg的参数传入。
linux下用C开发多线程程序,Linux系统下的多线程遵循POSIX线程接口,称为pthread。
由 restrict 修饰的指针是最初唯一对指针所指向的对象进行存取的方法,仅当第二个指针基于第一个时,才能对对象进行存取。对对象的存取都限定于基于由 restrict 修饰的指针表达式中。 由 restrict 修饰的指针主要用于函数形参,或指向由 malloc() 分配的内存空间。restrict 数据类型不改变程序的语义。 编译器能通过作出 restrict 修饰的指针是存取对象的唯一方法的假设,更好地优化某些类型的例程。
第一个参数为指向线程标识符的指针。
第二个参数用来设置线程属性。
第三个参数是线程运行函数的起始地址。
第四个参数是运行函数的参数。
因为pthread不是linux系统的库,所以在编译时注意加上-lpthread参数,以调用静态链接库。
终止线程:
如果在进程中任何一个线程中调用exit或_exit,那么整个进行会终止,线程正常的退出方式有:
(1) 线程从启动例程中返回(return)
(2) 线程可以被另一个进程终止(kill);
(3) 线程自己调用pthread_exit函数
#include
pthread_exit
线程等待:
int pthread_join(pthread_t tid,void **rval_ptr)
函数pthread_join用来等待一个线程的结束。函数原型为:
extern int pthread_join __P (pthread_t __th, void **__thread_return);
第一个参数为被等待的线程标识符,第二个参数为一个用户定义的指针,它可以用来存储被等待线程的返回值。这个函数是一个线程阻塞的函数,调用它的函数将一直等待到被等待的线程结束为止,当函数返回时,被等待线程的资源被收回。
对于windows线程的创建东西,就不列举了,msdn上 一搜就出来了。呵呵。今天就讲到这里吧,希望是抛砖引玉,大家一起探讨,呵呵。部分内容我也是参考internet的,特此对原作者表示感谢!
线程可以独立执行程序吗
Java同步
标签: 分类:
一、关键字:
thread(线程)、thread-safe(线程安全)、intercurrent(并发的)
synchronized(同步的)、asynchronized(异步的)、
volatile(易变的)、atomic(原子的)、share(共享)
二、总结背景:
一次读写共享文件编写,嚯,好家伙,竟然揪出这些零碎而又是一路的知识点。于是乎,Google和翻阅了《Java参考大全》、《Effective Java Second Edition》,特此总结一下供日后工作学习参考。
三、概念:
1、 什么时候必须同步?什么叫同步?如何同步?
要跨线程维护正确的可见性,只要在几个线程之间共享非 final 变量,就必须使用 synchronized(或 volatile)以确保一个线程可以看见另一个线程做的更改。
为了在线程之间进行可靠的通信,也为了互斥访问,同步是必须的。这归因于java语言规范的内存模型,它规定了:一个线程所做的变化何时以及如何变成对其它线程可见。
因为多线程将异步行为引进程序,所以在需要同步时,必须有一种方法强制进行。例如:如果2个线程想要通信并且要共享一个复杂的数据结构,如链表,此时需要
确保它们互不冲突,也就是必须阻止B线程在A线程读数据的过程中向链表里面写数据(A获得了锁,B必须等A释放了该锁)。
为了达到这个目的,java在一个旧的的进程同步模型——监控器(Monitor)的基础上实现了一个巧妙的方案:监控器是一个控制机制,可以认为是一个
很小的、只能容纳一个线程的盒子,一旦一个线程进入监控器,其它的线程必须等待,直到那个线程退出监控为止。通过这种方式,一个监控器可以保证共享资源在
同一时刻只可被一个线程使用。这种方式称之为同步。(一旦一个线程进入一个实例的任何同步方法,别的线程将不能进入该同一实例的其它同步方法,但是该实例
的非同步方法仍然能够被调用)。
错误的理解:同步嘛,就是几个线程可以同时进行访问。
同步和多线程关系:没多线程环境就不需要同步;有多线程环境也不一定需要同步。
锁提供了两种主要特性:互斥(mutual exclusion) 和可见性(visibility)。
互斥即一次只允许一个线程持有某个特定的锁,因此可使用该特性实现对共享数据的协调访问协议,这样,一次就只有一个线程能够使用该共享数据。
可见性要更加复杂一些,documents它必须确保释放锁之前对共享数据做出的更改对于随后获得该锁的另一个线程是可见的 —— 如果没有同步机制提供的这种可见性保证,线程看到的共享变量可能是修改前的?或不一致的?,这将引发许多严重问题
小结:为了防止多个线程并发对同一数据的修改,所以需要同步,否则会造成数据不一致(就是所谓的:线程安全。如java集合框架中Hashtable和
Vector是线程安全的。我们的大部分程序都不是线程安全的,因为没有进行同步,而且我们没有必要,因为大部分情况根本没有多线程环境)。
2、 什么叫原子的(原子操作)?
Java原子操作是指:不会被打断地的操作。(就是做到互斥 和可见性?!)
那难道原子操作就可以真的达到线程安全同步效果了吗?实际上有一些原子操作不一定是线程安全的。
那么,原子操作在什么情况下不是线程安全的呢?也许是这个原因导致的:java线程允许线程在自己的内存区保存变量的副本。允许线程使用本地的私有拷贝进
行工作而非每次都使用主存的?是为了提高性能(本人愚见:虽然原子操作是线程安全的,可各线程在得到变量(读操作)后,就是各自玩
弄自己的副本了,更新操作(写操作)因未写入主存中,导致其它线程不可见)。
那该如何解决呢?因此需要通过java同步机制。
在java中,32位或者更少位数的赋?是原子的。在一个32位的硬件平台上,除了double和long型的其它原始类型通常都
是使用32位进行表示,而double和long通常使用64位表示。另外,对象引用使用本机指针实现,通常也是32位的。对这些32位的类型的操作是原
子的。
这些原始类型通常使用32位或者64位表示,这又引入了另一个小小的神话:原始类型的大小是由语言保证的。这是不对的。java语言保证的是原始类型的表
数范围而非JVM中的存储大小。因此,int型总是有相同的表数范围。在一个JVM上可能使用32位实现,而在另一个JVM上可能是64位的。在此再次强
调:在所有平台上被保证的是表数范围,32位以及更小的?的操作是原子的。
3、 不要搞混了:同步、异步
举个例子:普通B/S模式(同步)AJAX技术(异步)
同步:提交请求->等待服务器处理->处理完返回 这个期间客户端浏览器不能干任何事
异步:请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)->处理完毕
可见,彼“同步”非此“同步”——我们说的java中的那个共享数据同步(synchronized)
一个同步的对象是指行为(动作),一个是同步的对象是指物质(共享数据)。
4、 Java同步机制有4种实现方式:(部分引用网上资源)
① ThreadLocal ② synchronized( ) ③ wait() 与 notify() ④ volatile
目的:都是为了解决多线程中的对同一变量的访问冲突
ThreadLocal
ThreadLocal 保证不同线程拥有不同实例,相同线程一定拥有相同的实例,即为每一个使用该变量的线程提供一个该变量?的副本,每一个线程都可以独立改变自己的副本,而不是与其它线程的副本冲突。
优势:提供了线程安全的共享对象
与其它同步机制的区别:同步机制是为了同步多个线程对相同资源的并发访问,是为了多个线程之间进行通信;而 ThreadLocal 是隔离多个线程的数据共享,从根本上就不在多个线程之间共享资源,这样当然不需要多个线程进行同步了。
volatile
volatile 修饰的成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的?。而且,当成员变量发生变化时,强迫线程将变化?回写到共享内存。
优势:这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个?。
缘由:Java
语言规范中指出,为了获得最佳速度,允许线程保存共享成员变量的私有拷贝,而且只当线程进入或者离开同步代码块时才与共享成员变量的原
始?对比。这样当多个线程同时与某个对象交互时,就必须要注意到要让线程及时的得到共享成员变量的变化。而 volatile
关键字就是提示 VM :对于这个成员变量不能保存它的私有拷贝,而应直接与共享成员变量交互。
使用技巧:在两个或者更多的线程访问的成员变量上使用 volatile 。当要访问的变量已在 synchronized 代码块中,或者为常量时,不必使用。
线程为了提高效率,将某成员变量(如A)拷贝了一份(如B),线程中对A的访问其实访问的是B。只在某些动作时才进行A和B的同步,因此存在A和B不一致
的情况。volatile就是用来避免这种情况的。
volatile告诉jvm,它所修饰的变量不保留拷贝,直接访问主内存中的(读操作多时使用较好;线程间需要通信,本条做不到)
Volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。这就是说线程能够自动发现 volatile
变量的最新?。Volatile
变量可用于提供线程安全,但是只能应用于非常有限的一组用例:多个变量之间或者某个变量的当前?与修改后?
之间没有约束。
您只能在有限的一些情形下使用 volatile 变量替代锁。要使 volatile 变量提供理想的线程安全,必须同时满足下面两个条件:
对变量的写操作不依赖于当前?;该变量没有包含在具有其他变量的不变式中。
sleep() vs wait()
sleep是线程类(Thread)的方法,导致此线程暂停执行指定时间,把执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复。调用sleep不会释放对象锁。
wait是Object类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态。
(如果变量被声明为volatile,在每次访问时都会和主存一致;如果变量在同步方法或者同步块中被访问,当在方法或者块的入口处获得锁以及方法或者块退出时释放锁时变量被同步。)
windows 怎样在调度线程到多核
线程是在操作系统层面上执行的一段程序,它可以在一个进程中独立运行。换句话说,线程可以独立执行程序。
在传统的单线程编程模型中,程序的执行是按照顺序逐行执行的,一次只能执行一个任务。但是,在多线程编程模型中,程序可以同时执行多个任务。每个线程都有自己的执行路径和执行上下文,可以独立执行一段程序代码。
线程的独立执行使得多个任务可以并发执行,提高了程序的效率和响应性。例如,在一个图形界面应用程序中,可以使用一个线程处理用户界面的交互事件,另一个线程同时执行耗时的计算任务,这样用户界面不会被阻塞,提供了更好的用户体验。
线程的独立执行还带来了一些挑战和注意事项。多个线程同时访问共享资源时可能会出现竞态条件(Race Condition)和死锁等并发编程问题。因此,在多线程编程中需要采取适当的同步机制,如互斥锁、信号量等,来保证线程之间的正确协调和资源的安全访问。
此外,线程的独立执行还需要考虑到系统资源的管理和调度。操作系统负责管理和调度线程的执行,根据不同的调度算法和优先级来决定哪个线程优先执行。线程的创建和销毁也需要操作系统来管理。
线程的工作原理的详细介绍:
1、线程的创建:线程的创建由操作系统的线程调度器完成。调度器为每个线程分配一个独立的执行上下文,包括程序计数器、寄存器和栈空间等。
2、线程的调度:操作系统的线程调度器负责决定哪个线程在何时执行。调度器使用调度算法(如抢占式调度算法)来确定线程的执行顺序和时间片分配。
3、线程的并发执行:当多个线程处于就绪状态时,调度器会根据调度算法选择一个线程执行。线程之间可以并发执行,共享进程的内存空间和资源。
4、线程的上下文切换:当调度器决定切换到另一个线程执行时,当前线程的上下文会被保存,包括程序计数器、寄存器和栈等。然后,调度器会加载另一个线程的上下文,并开始执行该线程。
5、线程的同步与通信:由于线程共享进程的内存空间,线程之间可以通过读写共享变量来进行数据的共享和通信。为了避免竞态条件和数据一致性问题,需要使用同步机制,如互斥锁、信号量等。
6、线程的销毁:线程的销毁由操作系统负责。当线程完成任务或被终止时,操作系统会回收它所占用的资源,包括内存空间和其他系统资源。
多线程是什么呀
法。
1 引言
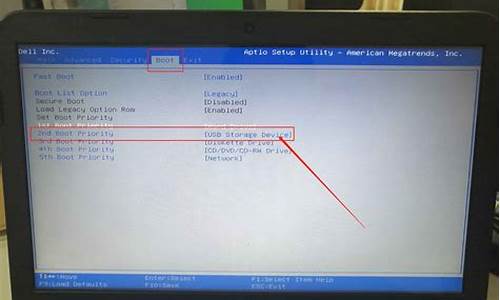
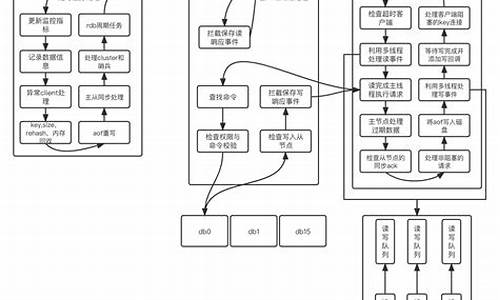
本文分析了Windows 系统的进程调度机制,并设计了一种基于Windows 操作系统内核驱动的多核CPU 线程管理方法,实现了一个基于Windows 内核驱动的线程管理服务系统,它能让用户根据每一个任务线程对CPU 资源的需要程度和对实时性的要求,在多核CPU上合理为线程分配CPU 核。
Windows 内核调度结构体关系图
图1 Windows 内核调度结构体关系图
2 Windows 系统的进程调度方法分析
Windows NT 中的每一个进程都是EPROCESS 结构体。此结构体中除了进程的属性之外还引用了其它一些与实现进程紧密相关的结构体。例如,每个进程都有一个或几个线程,线程在系统中就是ETHREAD 结构体。简要描述一下存在于这个结构体中的主要的信息,这些信息都是由对内核函数的研究而得知的。首先,结构体中有KPROCESS 结构体,这个结构体中又有指向这些进程的内核线程(KTHREAD)链表的指针(分配地址空间),基优先级,在内核模式或是用户模式执行进程的线程的时间,处理器affini ty(掩码,定义了哪个处理器能执行进程的线程),时间片值。在ETHREAD 结构体中还存在着这样的信息:进程ID、父进程ID、进程映象名。
在E P R O C E S S 结构体中还有指向P E B 的指针。
ETHREAD 结构体还包含有创建时间和退出时间、进程ID 和指向EPROCESS 的指针,启动地址,I/O 请求链表和KTHREAD 结构体。在KTHREAD 中包含有以下信息:内核模式和用户模式线程的创建时间,指向内核堆栈基址和顶点的指针、指向服务表的指针、基优先级与当前优先级、指向APC 的指针和指向T E B 的指针。
KTHREAD 中包含有许多其它的数据,通过观察这些数据可以分析出KTHREAD 的结构。图1 描述了这些结构体之间的关系。
通过遍历KPROCESS 结构体中的ETHREAD,找到系统中当前所有的KTHREAD 结构,这个结构中的偏移量为0x124 处的Affinity 域(Windows XP sp3)即为设置CPU 亲缘性掩码的内存地址。在此重点解释CPU 亲缘性的概念,CPU 亲缘性就是指在系统中能够将一个或多个进程或线程绑定到一个或多个处理器上运行,这是期待已久的特性。也就是说:“ 在1号处理器上一直运行该程序”或者是“在所有的处理器上运行这些程序,而不是在0 号处理器上运行”。然后, 调度器将遵循该规则,程序仅仅运行在允许的处理器上。在Windows 操作系统上,给程序员设定CPU 亲缘性的接口是用一个32 位的双字型数表示的, 它被称为亲缘性掩码(Affinity bitMask)。亲缘性掩码是一系列的二进制位,每一位代表一个CPU 单元是否可执行当前任务。例如一个在具有四个CPU 的PC 机上( 或四核CPU) ,亲缘性掩码的形式的二进制数如下式所示:
0000000000000000000000000000XXXXB
其中自右向左,每一位代表0 到31 号CPU是否可用,由于本机只有四个CPU, 所以只有前四个位可用,X 为1则代表当前任务可执行在此位代表的CPU 上,X 为0 则代表当前任务不可执行在此位代表的CPU 上, 例如:
00000000000000000000000000000010B
代表当前任务只能执行在1 号 CPU 上(CPU 下标记数从0 开始),又如0x00000004 代表当前任务只能执行在2 号CPU 上,0x00000003 代表当前任务可以运行在0号和1 号CPU 上。
Windows 的进程调度代码是在它的System 进程下的,所以它不属于任何用户进程上下文。调度代码在适当的时机会切换进程上下文,这里的切换进程上下文是指进程环境的切换, 包括内存中的可执行程序, 提供程序运行的各种资源.进程拥有虚拟的地址空间,可执行代码, 数据, 对象句柄集, 环境变量, 基础优先级, 以及最大最小工作集等的切换。而Windows 最小的调度单位是线程, 只有线程才是真正的执行体,进程只是线程的容器。Windows 的调度程序在时间片到期,或有切换线程指令执行(如Sleep,KeWaitForSingleObject 等函数)时, 将会从进程线程队列中找到下一个要调度的线程执行体,并装入到KPCR(Kernel ' s Processor Contr ol Re g i o n , 内核进程控制区域) 结构中,CPU 根据KPCR 结构中的KPRCB 结构执行线程执行体代码。而在多核CPU 下,当Windows 调度代码执行时,从当前要调度执行的KTHREAD 结构中取出Affinity,并与当前PC 机上的硬件配置数据中的CPU 掩码作与操作,结果写入到指定的CPU,例如双核CPU 的设备掩码为0x03,如果当前KTHREAD 里的Affinity 为0x01,那么0x01&0x03=0x01,这样执行体线程会被装入CPU1的KPRCB 结构中得以执行,调度程序不会把这个线程交给CPU2 去执行。此过程如图2 所示。这就是为线程选择指定CPU 核的原理。
Windows 内核亲缘性调度原理图
图 2 Windows 内核亲缘性调度原理图。
那么控制线程在指定CPU 上运行的突破口就是修改Windows 内核结构体KTHREAD 下的Affinity 域。然而Windows 内核结构被放在虚拟内存线性地址的高2G(不同版本Windows 下也可能是1G)地址空间,用户模式下的应用程序是无法访问这段内存空间的,所以必须编写Windows 驱动程序,来访问Windows 内核内存空间, 这也是本文将要描述的重点。
3 线程管理服务系统
整个系统的结构如图3 所示。该系统由两大部分组成,分别是内核模式下的管理服务系统设备驱动程序,和用户模式下的管理服务系统应用程序。管理服务系统应用程序通过调用Win32 子系统API,向内核下的管理服务系统驱动程序传递IRP,内核收到IRP 后,跟据收到的IRP 的内部信息,执行相应的派遣函数,对相应内存进行读写,从而给管理服务系统应用程序提供可用的系统信息。
管理系统总体结构图
图3 管理系统总体结构图。
3.1 内核模式下读取系统信息
线程管理服务系统驱动程序中,读取系统信息的方法用到了微软没有公开文档的内核服务函数,ZwQuerySystemInformATIon,这个函数被封装在ntdll.dll模块中,通过链接ntdll.lib 可得到此函数地址。通过一个枚举量SystemProcessInformation 来得到进程线程相关信息,填入到第二个输入参数SYSTEM_PROCESS_INFORMATION结构中, 这样就获得了当前系统关于进程线程的信息。
3.2 内核模式下枚举系统进程线程
SYSTEM_PROCESS_INFORMATION结构中存储了进程及其线程的所有相关信息,表1 列出了它的具体内容,包括结构内域的地址偏移, 数据类型和描述。
SYSTEM_PROCESS_INFORMATION的第一个DWORD型是下一个进程SYSTEM_PROCESS_INFORMATION相对于当前结构地址的偏移量,可以通过地址偏移来遍历所有的进程结构,当遇到某一个进程结构的0 x 0 0 0 0 处的DWORD 型值为0 时,说明这个结构体是系统内最后一个结构体。线程管理服务在它的派遣函数中通过这种方式遍历所有进程,从中提取有用的信息,填入两个自定义结构体中。如图4 所示,描述了一个具有两个线程的进程的数据结构,首先在MY_PROCESS_INFO 结构中填入进程的相关信息,然后根据此进程所有的线程数,向系统申请足够大的分页内存空间,PVOID 型指针指向的是第一个线程结构所在的地址空间,然后向线程结构体中_MY_THREAD_INFO 中填入线程信息,再由线程结构体中的PVOID 型指针指向第二个线程结构体所在的地址空间,以此类推,最后一个线程结构体的PVOID型指针指向NULL。这样一个过程描述了一个进程及其所属的所有线程的枚举过程,通过对所有进程的遍历,可以得到系统中的一个完整的进程线程表,存在一段分页内存中,这样在应用程序中便可以得到这些信息。
表1 SYSTEM_PROCESS_INFORMATION 结构
SYSTEM_PROCESS_INFORMATION 结构
进程线程的两种数据结构
图4 进程线程的两种数据结构。
3.3 线程管理服务系统应用程序设计
进程管理服务系统应用程序是要通过调用Win 32子系统的API 函数DeviceIoControl 来向线程管理服务系统驱动程序发送IRP 的,然后在IRP 结束之后把驱动程序中读出的所有有用进程线程信息填入到指定的内存中。这样线程管理服务系统应用程序就可以根据所获得的系统信息句柄来对线程CPU 亲缘性属性进行设置。首先为DeviceIoControl 中的InputBuffer 申请一段内存空间传入给驱动程序,驱动程序读取内核空间进程线程信息写入到这段内存中,应用程序读到信息并显示给用户。
在系统中应用程序为每一个CPU 维护一个结构体,内容包括该CPU 是否运行实时线程,该CPU 上运行的线程数(如果是实时线程CPU线程数为1),以及在此CPU上运行的线程结构数组的首地址。系统通过对此CPU 结构数组的解析来对线程进行管理。并通过DeviceIoControl函数把设置后的CPU 结构交给驱动程序内核。
3.4 修改Windows 内核结构体
在驱动程序读回应用程序下用户的设置结果后,就需要按照用户的设定修改KTHREAD 下的Affinity 域的掩码值了。首先要找到KTHREAD 的线性内存空间,PsGetCurrentProcess()内核函数可以返回内核下当前进程空间的E P R O C E S S 结构。E P R O C E S S 结构下的ActiveProcessLinks 域是LIST_ENTRY 结构,通过它可以遍历所有的ETHREAD 结构,那么那到KTHREAD 下的Affinity 域就不难了,可以使用两个循环嵌套来得到所有线程的Affinity 域并将其值设为应用程序中用户的设定值。线程CPU 掩码就被成功的修改了。当CPU 被设定为运行实时线程的CPU 时,在它上面运行的线程只能是一个实时线程,这时的运行线程数被设定为1; 当CPU被设定为非实时线程的时候,上面有可能除了任务线程运行之外,还有Windows 系统进程下的线程。
4 软件使用及性能测试
4.1 驱动的加载及软件的使用
首先需要把本系统的驱动sys 文件加载到Windows的服务管理器中,加载成功后打开应用程序,用户可以通过应用程序中显示出的当前系统内的进程和线程进行选择,并在GUI 图形界面中对其CPU 占用率及CPU亲缘性进行设置。
4.2 设置 CPU 亲缘性测试
测试运行在双核CPU 的PC 机上,系统运行一个要测试的任务线程(任务线程为一个108 次加法运算),四个其它线程(为测试方便,设为while 循环线程),限定了循环线程的CPU 亲缘性掩码为0x0001,任务线程的CPU亲缘性为0x0002,这样任务线程与其它线程分别在两个核上运行,分别测试了任务线程单独运行,任务线程与其它线程不设定CPU 亲缘性,任务线程与其它线程设定CPU 亲缘性三种情况下下任务线程的运行总时间如表2 所示。
表2
从表2 分析, 设定任务线程的CPU 亲缘性与其它线程所占用的CPU 分开,真正意义上的实现了任务的异步执行,非常有效的提高了实时线程对CPU 资源的使用率。
5 结束语
本文分析了Windows 系统的内核进程线程调度表2CPU 亲缘性设定三种情况下任务线程运行时间表机制,并在此基础上设计了一种基于Windows 操作系统内核驱动的多核CPU 线程管理方法, 实现了这样一个软件系统。首先在Windows 内核层获取系统进程线程信息,然后再把信息传入应用层,由应用层上的应用程序根据获取的信息句柄,对进程进行操作,用户在图形界面下按照仿真任务对CPU 资源的不同需求,进行相应的设置,可以为指定线程设置CPU 亲缘性的功能。在一定程度上为Windows 系统下的任务合理地分配了CPU 资源,为对实时性要求较高的任务提供了一个可靠的运行环境。
多线程编程怎么回事啊
Windows是一个多任务的系统,如果你使用的是windows 2000及其以上版本,你可以通过任务管理器查看当前系统运行的程序和进程。什么是进程呢?当一个程序开始运行时,它就是一个进程,进程所指包括运行中的程序和程序所使用到的内存和系统资源。而一个进程又是由多个线程所组成的,线程是程序中的一个执行流,每个线程都有自己的专有寄存器(栈指针、程序计数器等),但代码区是共享的,即不同的线程可以执行同样的函数。多线程是指程序中包含多个执行流,即在一个程序中可以同时运行多个不同的线程来执行不同的任务,也就是说允许单个程序创建多个并行执行的线程来完成各自的任务。浏览器就是一个很好的多线程的例子,在浏览器中你可以在下载JAVA小应用程序或图象的同时滚动页面,在访问新页面时,播放动画和声音,打印文件等。
多线程的好处在于可以提高CPU的利用率——任何一个程序员都不希望自己的程序很多时候没事可干,在多线程程序中,一个线程必须等待的时候,CPU可以运行其它的线程而不是等待,这样就大大提高了程序的效率。
然而我们也必须认识到线程本身可能影响系统性能的不利方面,以正确使用线程:
线程也是程序,所以线程需要占用内存,线程越多占用内存也越多
多线程需要协调和管理,所以需要CPU时间跟踪线程
线程之间对共享资源的访问会相互影响,必须解决竞用共享资源的问题
线程太多会导致控制太复杂,最终可能造成很多Bug
基于以上认识,我们可以一个比喻来加深理解。假设有一个公司,公司里有很多各司其职的职员,那么我们可以认为这个正常运作的公司就是一个进程,而公司里的职员就是线程。一个公司至少得有一个职员吧,同理,一个进程至少包含一个线程。在公司里,你可以一个职员干所有的事,但是效率很显然是高不起来的,一个人的公司也不可能做大;一个程序中也可以只用一个线程去做事,事实上,一些过时的语言如fortune,basic都是如此,但是象一个人的公司一样,效率很低,如果做大程序,效率更低——事实上现在几乎没有单线程的商业软件。公司的职员越多,老板就得发越多的薪水给他们,还得耗费大量精力去管理他们,协调他们之间的矛盾和利益;程序也是如此,线程越多耗费的资源也越多,需要CPU时间去跟踪线程,还得解决诸如死锁,同步等问题。总之,如果你不想你的公司被称为“皮包公司”,你就得多几个员工;如果你不想让你的程序显得稚气,就在你的程序里引入多线程吧!
本文将对C#编程中的多线程机制进行探讨,通过一些实例解决对线程的控制,多线程间通讯等问题。为了省去创建GUI那些繁琐的步骤,更清晰地逼近线程的本质,下面所有的程序都是控制台程序,程序最后的Console.ReadLine()是为了使程序中途停下来,以便看清楚执行过程中的输出。
每个正在系统上运行的程序都是一个进程。每个进程包含一到多个线程。进程也可能是整个程序或者是部分程序的动态执行。线程是一组指令的集合,或者是程序的特殊段,它可以在程序里独立执行。也可以把它理解为代码运行的上下文。所以线程基本上是轻量级的进程,它负责在单个程序里执行多任务。通常由操作系统负责多个线程的调度和执行。
什么是多线程?
多线程是为了使得多个线程并行的工作以完成多项任务,以提高系统的效率。线程是在同一时间需要完成多项任务的时候被实现的。
使用线程的好处有以下几点:
·使用线程可以把占据长时间的程序中的任务放到后台去处理
·用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
·程序的运行速度可能加快
·在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
还有其他很多使用多线程的好处,这里就不一一说明了。
一些线程模型的背景
我们可以重点讨论一下在Win32环境中常用的一些模型。
·单线程模型
在这种线程模型中,一个进程中只能有一个线程,剩下的进程必须等待当前的线程执行完。这种模型的缺点在于系统完成一个很小的任务都必须占用很长的时间。
·块线程模型(单线程多块模型STA)
这种模型里,一个程序里可能会包含多个执行的线程。在这里,每个线程被分为进程里一个单独的块。每个进程可以含有多个块,可以共享多个块中的数据。程序规定了每个块中线程的执行时间。所有的请求通过Windows消息队列进行串行化,这样保证了每个时刻只能访问一个块,因而只有一个单独的进程可以在某一个时刻得到执行。这种模型比单线程模型的好处在于,可以响应同一时刻的多个用户请求的任务而不只是单个用户请求。但它的性能还不是很好,因为它使用了串行化的线程模型,任务是一个接一个得到执行的。
·多线程块模型(自由线程块模型)
多线程块模型(MTA)在每个进程里只有一个块而不是多个块。这单个块控制着多个线程而不是单个线程。这里不需要消息队列,因为所有的线程都是相同的块的一个部分,并且可以共享。这样的程序比单线程模型和STA的执行速度都要块,因为降低了系统的负载,因而可以优化来减少系统idle的时间。这些应用程序一般比较复杂,因为程序员必须提供线程同步以保证线程不会并发的请求相同的资源,因而导致竞争情况的发生。这里有必要提供一个锁机制。但是这样也许会导致系统死锁的发生。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。